
(この記事はあしたのクラウド のインフラ移行に関する連載記事です)
こんにちは、あしたのチームでバックエンドエンジニア時々 SRE をやっている @snaka です。
今回は定時バッチの監視というテーマでお話したいと思います。
定時バッチとは
この記事で言及する「定時バッチ」とは、「一定間隔で実行されるシステムの処理」を指しています。旧インフラでは複数ある EC2 インスタンスの 1 つで cron によってバッチジョブのスケジュールを管理していました。
あしたのクラウドにおける定時バッチとして、以下のような処理が存在します。
- 配信予約されたメールを送信する
- 予約された社員情報の更新を反映する
- etc.
定時バッチが起動していない問題
新インフラへ移行が完了し、発生する問題の対応に追われる状況が落ち着いてきたかな? と思い始めたころにその問題は発覚しました。
どうやら一部の定時バッチが起動していないらしい... 😨 と
原因
バッチが起動していない原因は以下のようなものでした。
- ECS Scheduled Task の実行時間のタイムゾーンを勘違いしていた
- Task から起動するコマンドの指定方法に誤りがありコマンドの実行自体に失敗していた
- 旧インフラリソースの整理時に誤って ECR リポジトリを削除していた
のように、SREの作業ミスによって定時バッチが実行されていないケースが発生していました。
ポストモーテム
問題の発覚後、SRE チームでポストモーテムを実施しました。
ポストモーテムは Google の SRE Book などでも紹介されていて、すでによく知っている方も多いかと思います。
ひとことで言うと、「失敗とその原因を関係者間で共有し学びの機会とする」というような事だと認識しています。今回のインフラ移行をきっかけに編成された SRE チームによって導入された取り組みの中のひとつでもあります。
問題点と対策
ポストモーテムで話し合った結果、まず手を打つべき問題は「SREが定時バッチ処理の問題に気付くまでの時間が長い(数時間から数日)」というものでした。
当時、Sentry によって例外の発生を検知して Slack に通知されるしくみは構築されていました。しかし、コンテナの起動に失敗してバッチ処理自体が実行されないケースについては自発的にログを参照し、処理開始/終了のログの有無で判断するしか無い状況でした。
そのような状況でしたので、まずは 「定時バッチで問題が発生した際、お客様からの問い合わせより先に SRE がその状況を把握している」 という状態を目指すことにしました。
CloudWatch Metrics Filter によるデッドマン装置
最初に試したのは CloudWatch Metrics Filter による「デッドマン装置」の実装です。
デッドマン装置は 入門監視(O'Reilly Japan)の「8.12 スケジュールジョブの監視」で以下のように紹介されています。
監視する中でやりにくいことの 1 つは、一見シンプルそうな、データがないこと で何かがおかしくなるというスケジュールされたタスクや cron ジョブを監視するこ とです。
(中略)
やりたいのは、データ が存在していないことを検知することです。このような場合の解決策は、デッドマン 装置(dead man's switch) として知られています。これは、何らかの仕組みがアク ションを止めるように指示するまではあるアクションを行う、という仕組みです。
この記事では実装の詳細については触れません、具体的な実装方法を知りたい方は以下のような記事が参考になるでしょう。
デッドマン実は死んでなかった問題
そうしてデッドマン装置をしばらく稼働させてみて問題が無いようにみえましたが、「実際はバッチが実行されているのにバッチが実行されていない」と誤った通知が飛ぶという状況にしばしば遭遇しました。 その原因として以下が考えられました。
※ 1時間に1回という周期で起動するバッチという前提
- CloudWatch Metric Filter はきっちり1時間毎にログの件数をカウントしている。
- ECS Scheduled Task は起動して処理が動き出すまでの時間にばらつきがある。
- たまたま Task が起動していないタイミングで CloudWatch Alarm がメトリクスを参照してしまうと、バッチが起動していないと判断して Alarm 状態となる。
問題は「処理が動き出すまでの時間にばらつきがある」という点だとすると、CloudWatch Alarm で検査する時間の幅に多少の余裕を持たせればよさそう、というアイデアが浮かびました。
しかし、そのアイデアも CloudWatch Alarm の制限でメトリクスの間隔(Period)は最長で1日という事実が判明しボツとなりました。
頑張れば CloudWatch でなんとかなりそうな気もしましたが、必要以上に監視を複雑にしてしまうと監視そのものの信頼性が問題となりそうな気配もあり、一旦 CloudWatch でのデッドマン装置の実装はあきらめました。
Healthchecks.io
バッチの監視について良い方法が無いか探しているうちに突き当たったのが以下のブログ記事でした。
記事を読む限りよさそうな雰囲気を感じました。 OSS版もあるということですが、今以上に管理対象を増やしたくないということもあり SaaS版の方を試用してみました。
使ってみて以下の点を気に入り、すぐに有償プランへと切り替えました。
- 組み込みのために特別な Gem などが不要
- 猶予期間 (Grace Time) を設定することができる
- たとえば 10 分の猶予期間を設定したとき、予定時刻から10分間は Ping が無くてもアラートは飛んできません。
- CloudWatch での監視で問題になった ECS Scheduled Task の起動時間にばらつきがある問題はこれで解消しました。
- Slack への連携が簡単
- INTEGRATIONS ページで Slack の通知先チャンネル等の設定を行うだけ
プロダクトの状況次第では OSS 版を導入するというのもアリかもしれません。
Healthchecks.io の設定を Terraform で管理する
新インフラでは IaC を基本としているため、当然 Healthchecks.io の設定も画面ポチポチではなく Terraform 化しています。
非公式ではありますが以下のプロバイダが公開されています。
参考までに Terraform での実装は以下のような感じになります(一部抜粋)
terraform { required_providers { healthchecksio = { source = "kristofferahl/healthchecksio" } } } locals { checks = { fooooo-deliver: { # 監視スケジュールは cron と同様の記法で書くことも、「1 hours」のような形で設定することも可能 schedule: "0 * * * *", desc: "bundle exec rake foo:deliver", grace: 900, # 猶予期間 15 minutes tags: ["every_hours"] }, baaaar-deliver: { schedule: "5 * * * *", desc: "bundle exec rake bar:deliver", grace: 900, # 猶予期間 15 minutes tags: ["every_hours"] }, } } data "healthchecksio_channel" "slack" { kind = "slack" } resource "healthchecksio_check" "this" { for_each = local.checks name = each.key desc = each.value.desc tags = concat(each.value.tags, [each.key]) grace = each.value.grace schedule = each.value.schedule timezone = "UTC" # ECS Scheduled Task の設定が UTC ベースであるため、それに合わせて監視のスケジュールも UTC ベースとしている channels = [ data.healthchecksio_channel.slack.id ] }
Slack 経由で通知を受け取ってみる
さて、設定もひととおり済んだので早速どのように通知が飛んでくるのか確認してみます。
バッチ処理が時間どおりに実行されなかった場合は以下のような通知が Slack に飛んできます。
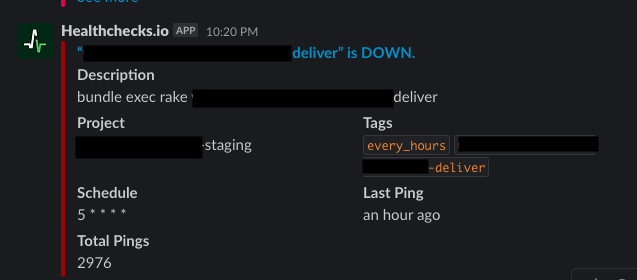
問題が解消してバッチが動くと以下のような通知が飛んできます。
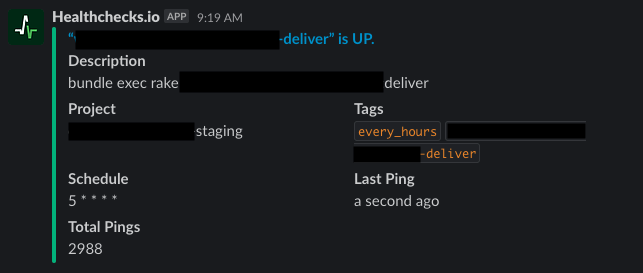
このように、正常⇔異常の状態遷移のタイミングで通知が飛ぶようになっているため、普通に運用していれば通知で Slack チャンネルが通知で溢れるということもありません。
これまで監視ができていなかった定時バッチに対して監視するしくみを構築することができ、これでやっとサービス品質向上へのスタートライン*1に立てたのではないかと思っています。
さいごに
今回、あしたのクラウドにおける定時バッチの実行状況が監視できていないという課題に対して、最初の試みとして CloudWatch Metrics Filter を使ったデッドマン装置の実装で対応し、そして最終的に Healthchecks.io に落ち着いたという経緯についてお話しました。
この記事が同じような状況で困っているエンジニアの役に立てれば幸いです。 それではまたー 👋
あしたのチームではプロダクトの成長と品質を支える SRE を募集中です。 "我こそは"という方いらっしゃいましたら 求人一覧 のページよりご応募ください 🙋♂️