
もうすっかり年末な今日この頃いかがお過ごしでしょうか? あしたのクラウド開発チームでバックエンドエンジニア兼SREをしている @snaka です。
年末と言えば大掃除ですが、去る 2021 年 10 月 9 日にあしたのクラウドの開発チームにおける大掃除とも言えるイベントとしてインフラ移行を実施しました。
インフラ移行プロジェクトでは、その準備から完了するまでの過程では多くの失敗や試行錯誤を経て多くの知見を得ることができました。
それらの知見をこれから数回にわたって連載記事という形で共有します。
なぜインフラ移行が必要だったのか?
連載を始めるにあたって、まずインフラを移行するという判断に至った経緯を共有したいと思います。
移行前のインフラ構成は以下のとおりでした。
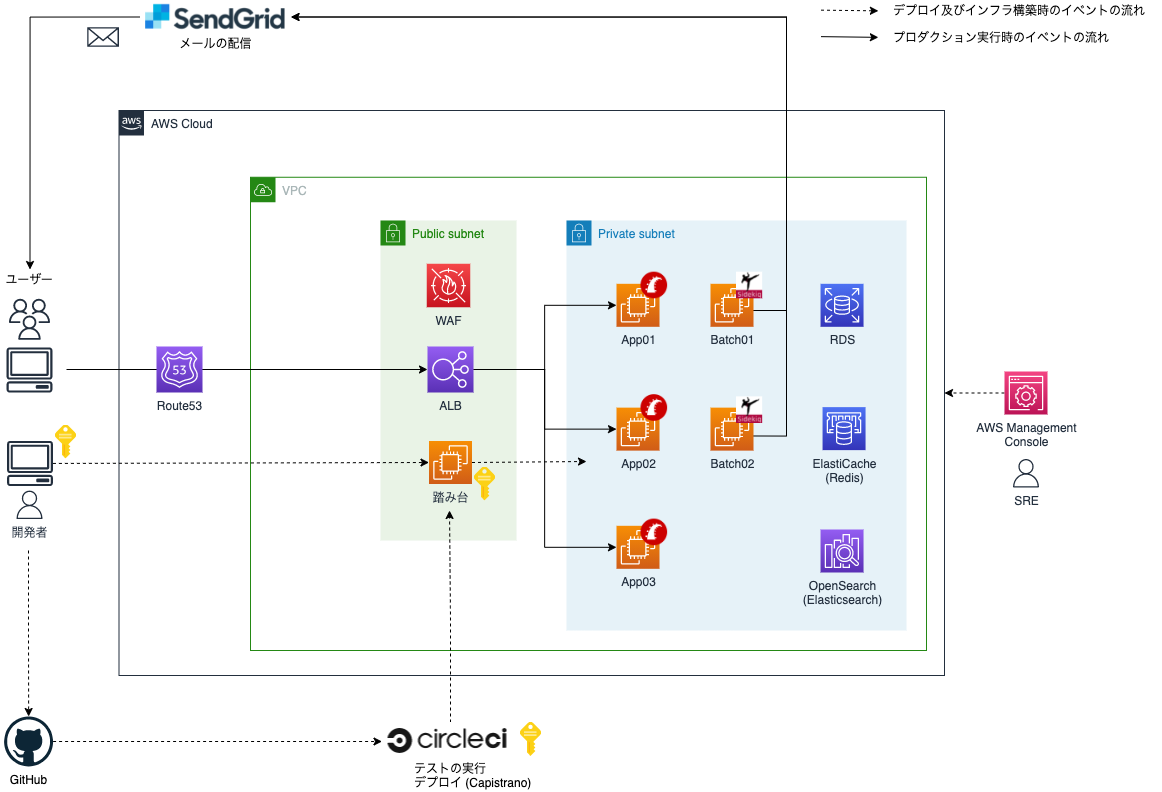
移行前のインフラでは以下のような問題がありました。
- OS やライブラリの更新がツライ問題
- 動作確認環境の追加が簡単に行えない問題
OS やライブラリの更新がツライ問題
インフラ移行プロジェクトが開始された 2021年2月時点、当時稼働していた EC2 インスタンスで利用していたOS (Amazon Linux) は既にEOL を迎えていました。
そのため、できるだけ早く、 安心してアプリケーションを稼働し続けられる環境を用意し、プロダクション環境をそちらに移行する必要がありました。
しかし、当時のインフラは以下の状態でした。
- アプリケーションやミドルウェアの設定情報はバージョン管理されておらず、稼働中のシステム上で設定の追加・更新が続けられた、いわゆる「秘伝のタレ」状態でした。
- AWSリソースはエンジニアが必要時にAWS コンソール上でポチポチして作成している状態でした。
- 稼働中の EC2 インスタンスに OS やライブラリを更新するためには、ロードバランサからの切り離しやインスタンスの再起動などが必要でしたが、これらを手作業で実施する必要がありました。
これらのことから、複数存在する開発環境やプロダクション環境の OS やライブラリを更新する作業は人的コストやリスクが非常に高い状態でした。
その結果、それらの作業は後回しになりがちでした。
動作確認環境の追加が簡単に行えない問題
インフラ構築作業という点では以下のような状況でした。
- 当時はAWSコンソールから手作業でインフラ構築していたため、作業する人やタスクの調整が必要となり、新しい環境を作成するのが難しい状態でした。
- 簡単に追加が行えないということは、逆に言うと簡単に環境を削除できず、当面使わない環境も残し続けている状態でもありました。
これらの要因から、動作確認環境を利用したいタイミングで利用できずに順番待ちが発生したり、誰がどのような理由で作成したのかわからない環境が存在している状態でした。
インフラ移行後
移行後のインフラ構成は以下の図のとおりになりました。
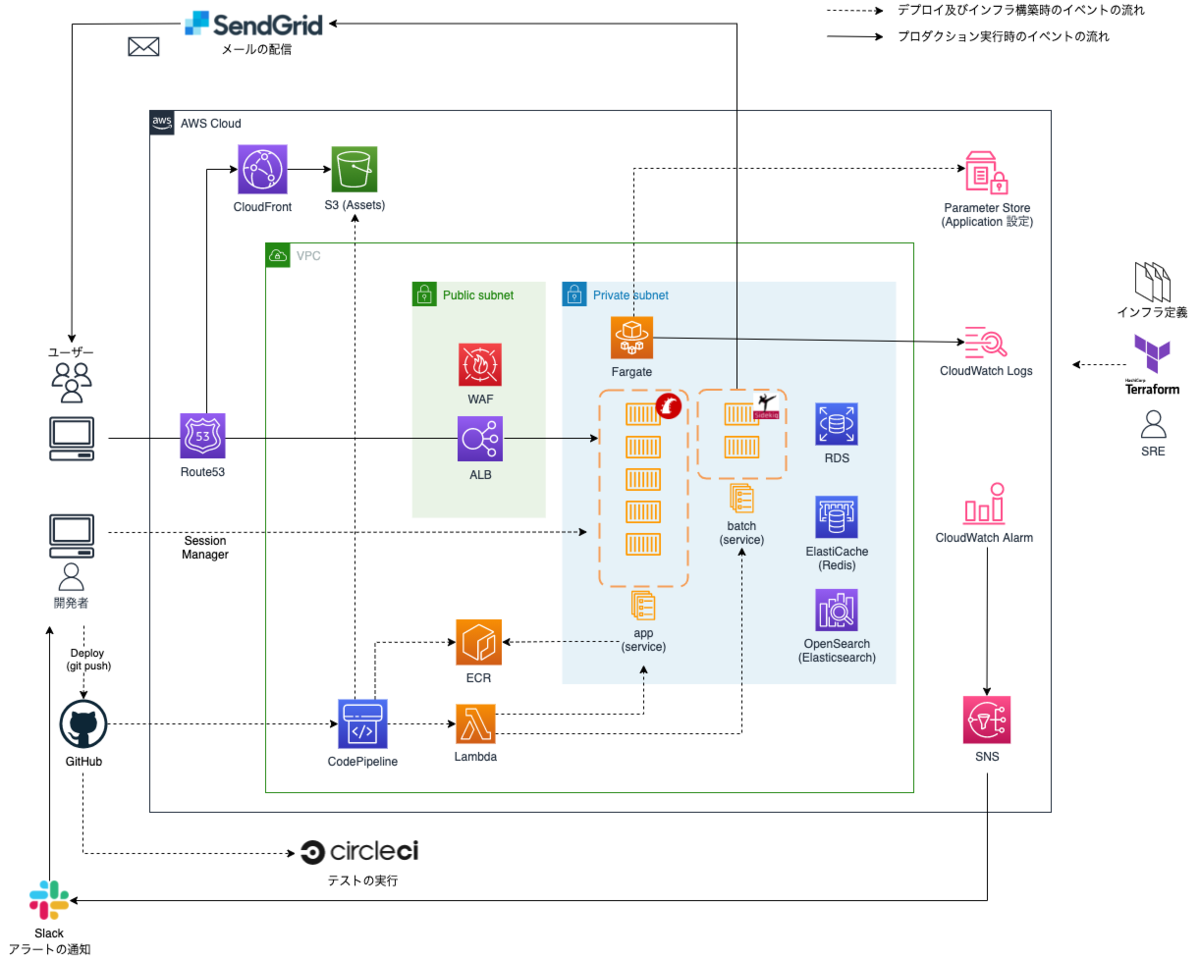
新しいインフラでは前述の問題を以下のように解決しました。
サーバレス化とコンテナ化
- Fargate を採用したことで EC2 インスタンスの管理が不要になりました。
- 普通にデプロイを実行するだけで最新のセキュリティパッチ*1が適用された環境でアプリケーションが動作します。
- サービスのタスク数の設定を変更するだけでスケールアウト・スケールインが可能です。
- コンテナ化によってアプリケーションの依存するライブラリが Dockerfile で管理できるようになりました。
- それによってライブラリのバージョン管理が楽になりました。
これで「OS やライブラリの更新がツライ問題」が解消されました。
Terraform によるインフラのコード化
- インフラ構築手順がコードという目に見える形となったことで、レビューや知識の共有がしやすくなりました。
- インフラ構成の変更の経緯が Git のコミット履歴や Pull Request として参照できるようになり、過去の経緯を追いかけやすくなりました。
- 手作業が大幅に減ったことで、環境の追加や削除が以前よりカジュアルに行えるようになりました。
これで「環境が簡単に増やせない問題」が解消されました。
その他よかったこと
先に挙げた問題の解消だけではなく、以下のような効果がありました。
- ステージング環境とプロダクション環境の AWS アカウントが別になったことで、安心してステージング環境で作業が行えるようになりました。
- アプリケーションのログが CloudWatch Logs に集約されたことでログの調査や分析が楽になりました。
- ECS Exec によって SSH のための踏み台サーバが不要になり、煩雑だった接続用の設定ファイルや鍵の管理からも開放されました。
さいごに
このようにインフラ移行によってセキュリティリスクやインフラ作業に対する不安が軽減されて良いことだけのようにも見えますが... 移行の過程ではいくつか問題も発生し、その対応に追われる時期もあったのでした...
そのあたりの詳細についてはこの連載の中で取り上げていく予定ですのでお楽しみに(?) 😉
それでは、今年も残りあとわずかですがよいお年をお過ごしください。
(以下のカテゴリページから連載記事をまとめて読むことができます)