(この記事はあしたのクラウド のインフラ移行に関する連載記事です)
先日、約一年間かけてようやくリングフィットアドベンチャーをクリアして、ちょっとだけ筋肉の成長を感じている @snaka です。
今回は「定時バッチのしくみ」の改善についてお話します。
移行前の定時バッチのしくみ
移行前のインフラ構成では、定時バッチを cron で実行するという伝統的な手法をとっていました。
おおよそのしくみは以下のとおりです。
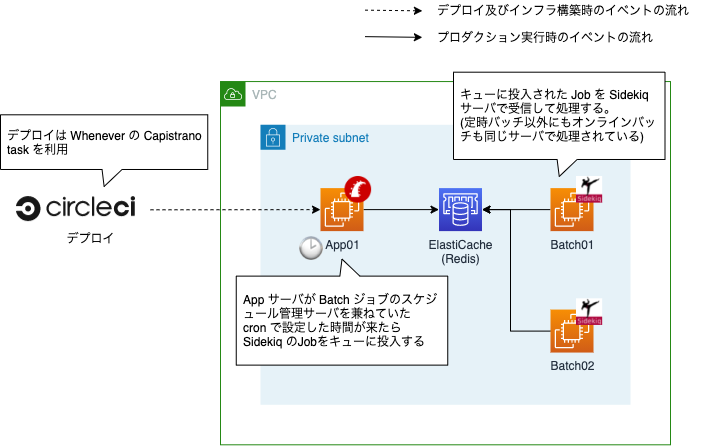
- EC2インスタンスの一つで cron を稼働させておく ( 3台構成の App サーバうち 1 台で実行していました )
- cron で実行されるスクリプトでは基本的に Sidekiq のキューにジョブを投入して終了する
- バッチサーバで起動している Sidekiq でキューを監視してジョブが投入されたらそれを受け取り実行する
- スケジュールのデプロイは whenever を使用
このしくみの問題
このしくみには以下のような問題がありました。
- cron を稼働しているが止まっているとバッチが実行されない
- 現在のスケジュール設定を確認するには SSH でサーバに入って
crontab -lコマンドを叩く必要がある
では、新しいインフラではどのよう変わったのか見ていきます。
新しい定時バッチのしくみ
新しいインフラでの定時バッチの仕組みは以下のようになりました。
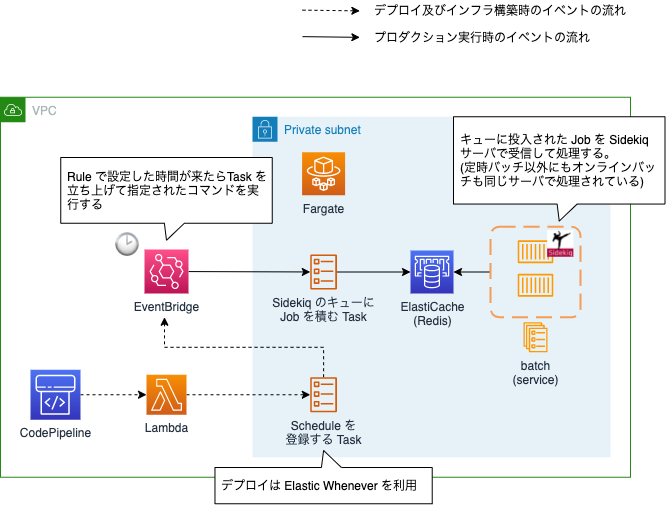
- ECS Scheduled Task で実装
- 設定されたスケジュールに従い ECS 上で Task を起動し指定されたコマンドを実行する
- スケジュールのデプロイは Elastic Whenever を使用する
cron を実行するサーバが不要になって、バッチサーバ自体も ECS のオートスケーリング設定で Task の負荷に応じてスケールするようになっています。
Elastic Whenever について
Elastic Whenever は Whenever の ECS Scheduled Task 対応版みたいなもので、Whenever とほぼ同じような書式で定期実行する Task をコードで管理することができます。
数年前、同じように ECS で定時バッチを運用したくてデプロイどうするか悩んでいたときに以下のブログをきっかけに存在を知りました。
ECS Scheduled Task の実態は Amazon EventBridge 上のスケージュールベースの Rule です。
EventBridge の Rule は AWS リソースですので Terraform で管理するという方法も考えられます。 では、Terraform ではなく Elastic Whenever を選択したのはなぜでしょうか?
理由は以下のとおりです。
- バッチの起動方法や実行すべきタイミングは主に「アプリケーション側」の関心事である
- アプリケーション側の都合で変更が入ったときにインフラ側も合わせて変更が必要になることを避けたい
- Elastic Whenever であれば、コマンドを実行するだけでスケジュールが反映できるので、CodePipeline に組み込むのも簡単そう
- Whenever で利用していた
config/shedule.rbがほぼ同じ形で利用できる
後から知ったのですが、同じように ECS Scheduled Task 設定を管理するCLIベースのツールで ecschedule というのもあるんですね。
ちなみに、たまたま見かけた以下の記事で存在を知りました。
見た感じGoで実装されてるようで、実行するコンテナに Ruby の実行環境を用意しなくても良くてシンプルに運用できそうな気がしてます。
今度同様のインフラを構築する機会があれば、こちらも検討対象として良いかもしれないと思いました。
ECS Scheduled Task の問題?
ECS Scheduled Task にしたことで cron を実行するためのサーバが不要になったのは良いのですが、1点だけ問題があります。
それは、 Task の起動に時間がかかるということです。
移行後のしくみでは、設定した時間になると Fargate で必要なリソースを Provisioning し、その後 Task が立ち上がって指定されたコマンドを実行するという実行プロセスになります。
この実行プロセスには約2分程度かかります。
この2分が問題になるほど遅いかというと状況によると思いますが、結果としてあしたのクラウドでのバッチ処理においては特に問題になるものではありませんでした。
実行タイミングにシビアなユースケースでは ECS Scheduled Task ではない別の方式を検討したほうが良いかもしれません。
さいごに
インフラ移行前は cron による定時バッチ運用だったものが、移行後のインフラでは Fargate + ECS Scheduled Task なサーバレスなバッチ運用に切り替えることができました。
また、サーバレスになったことで SRE の作業も楽になったと感じています。
ただ、この変更によって全く問題が発生しなかったのか?と言うとそうでもありません。
それらの問題についてはまた別の記事で取り上げたいと考えています。